
Manual for Using the SHE Corpus Analysis Software via the Web Interface
This page aims to provide a user-friendly guide to the web version of the corpus analysis software developed by Shane Sheehan and Saturnino Luz for the Sustainability & Health (SHE) Corpus.
Information about the content of the SHE Corpus is available here.
Should you encounter any software bugs or other technical problems when using this interface, please create a ticket detailing the nature of the issue on our SourceForge project page.
While the interface will work well, to varying degrees, on most browsers, we recommend that you use Chrome or Firefox for optimal performance.
Table of contents
- Overview
- Menu
- Selection Tools: Corpus Selection – See note on language
- Save/Load Concordance
- Analysis Tools
- Corpus Settings
- Mosaic Visualization
- Metafacet Visualization
Overview
When you access the web interface you will see three windows: a sample concordance of ‘keyword’; a mosaic visualization of ‘keyword’ with its main collocates in four positions to the left and four positions to the right; and a Metafacet display of attributes associated with the concordance lines for ‘keyword’. Every time you visit the site it will default to this display, until you enter a new search word.
Each of these windows has a handle at the righthand bottom of the window, which you can use to enlarge or reduce the size of that window (and simultaneously bring the other windows into less or more prominent view). These handles look different on different browsers. In Chrome, the handle looks as shown at the righthand bottom of the concordance window below:
Instructions on how to use Mosaic and Metafacet and an explanation of how they interact with the concordance are detailed below.
Concordance Browser
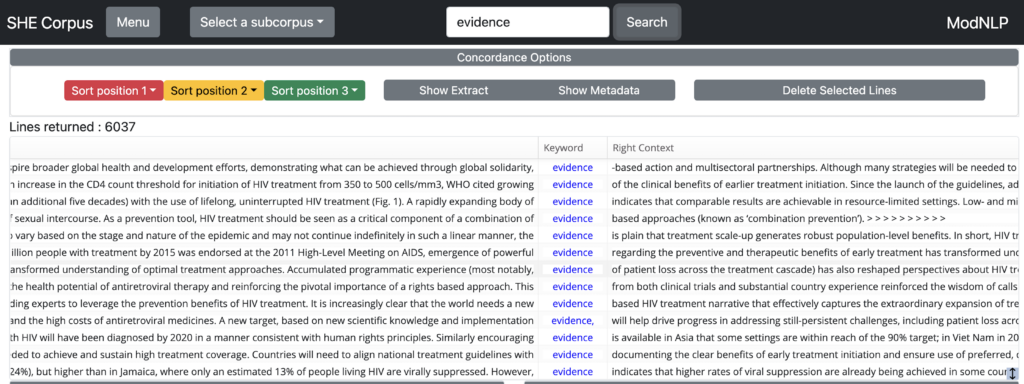
The main page of the web interface displays a short concordance of ‘keyword’ unless a different search item is entered into the search box.
A search on another keyword will populate the concordance browser window, displaying the Filename, Left Context, Keyword and Right Context for each line of text in the corpus that matches this search string.
Scroll to the left or right to see the source of each line and a longer stretch of co-text:

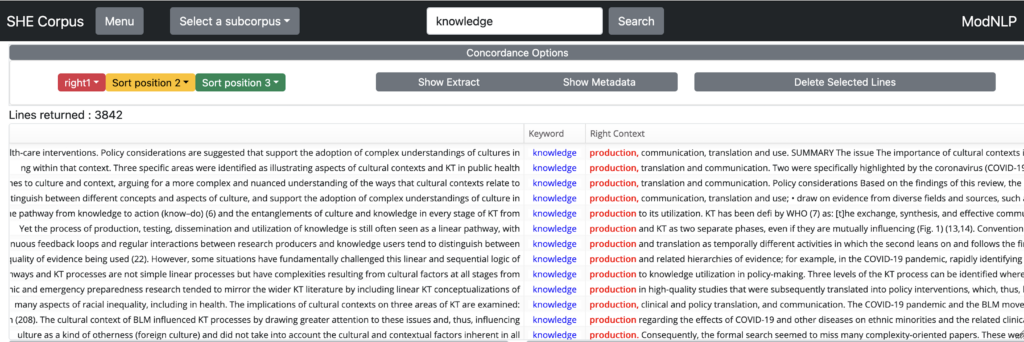
Note that the width of each column can also be adjusted manually by clicking and dragging the divider bars separating each column header. This is often useful when working with unusually long or short keywords.
Scroll up and down to see more of the concordance. You can also grab the handle at the bottom righthand side of the concordance to expand or reduce the size of the concordance window.
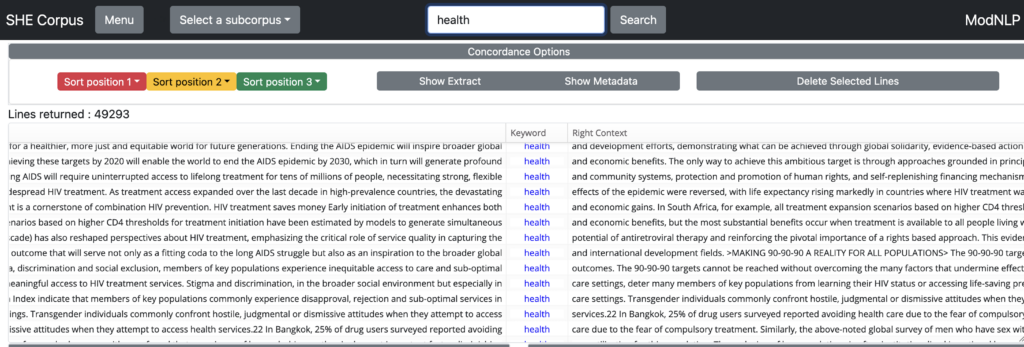
The total number of ‘hits’ for the search query is displayed at the top lefthand corner of the corpus browser window. In the screenshot below, for example, the software tells us that there are 49293 instances of the keyword health in the corpus selected.
Search options
The search function is by default not case-sensitive and does not distinguish between accented and non-accented characters. So a search for ‘WHO’ will retrieve both the organization WHO and the pronoun ‘who’; a search for exposé will return also return all instances of expose. To restrict the search to, e.g., WHO or exposé , activate ‘Case/diacritic sensitive’ under Corpus Settings in the top Menu.
Wildcards
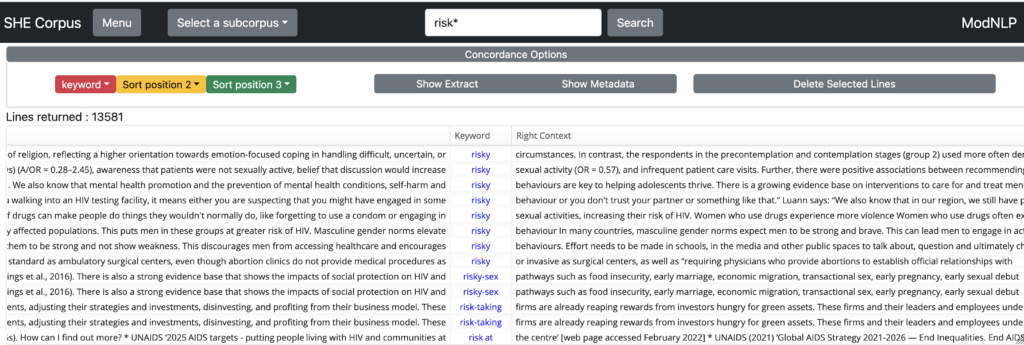
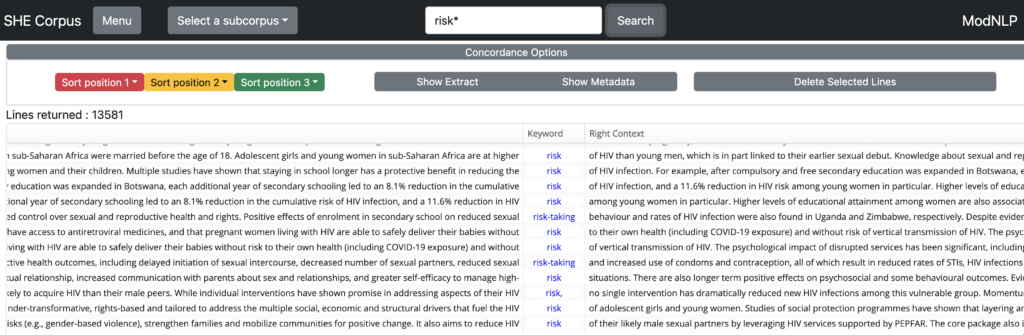
The * symbol may be used to represent any string of characters of any length. For example, searching risk* will retrieve a concordance containing all words which start with risk (e.g. risk, risks, risked, risky, etc):
Sequences
You can also specify sequences of keywords and/or wildcards, and the maximum number of intervening words you wish to allow between each element in the sequence.
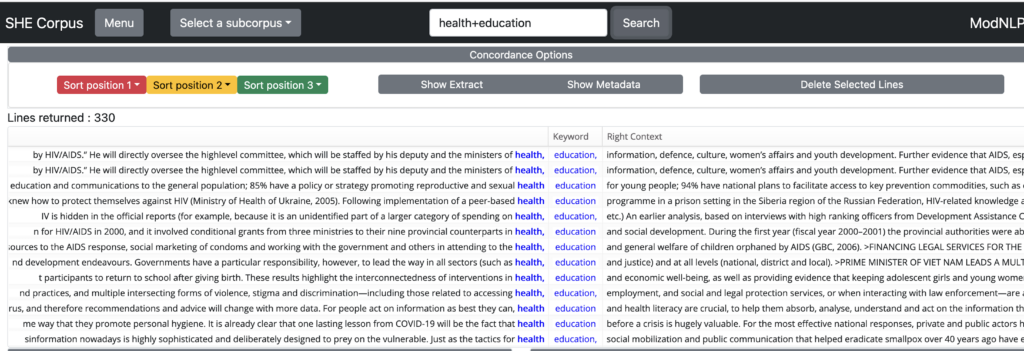
For example, entering health+education will return every instance in which these two words appear next to one another (and in this order):
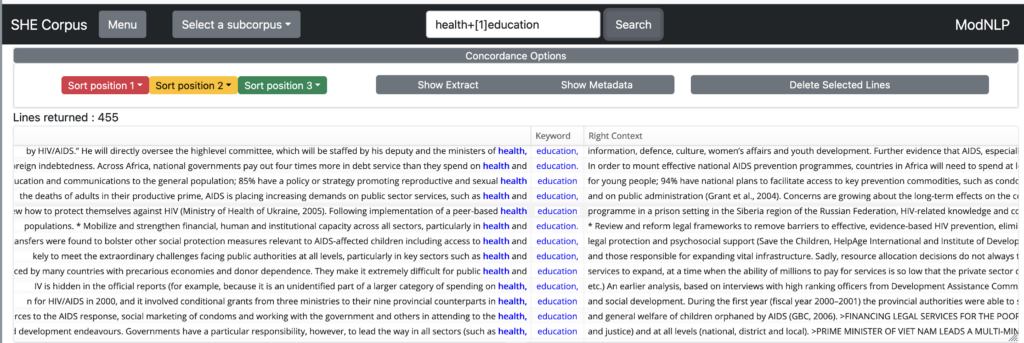
Entering health+[1]education finds, in addition, …health and education…, …health/sexuality education, health to education…, i.e., all sequences in which there is at most one word between ‘health’ and ‘education’:
Entering health+[2]education finds, in addition, stretches such as Health and Medical Education and health and hygiene education, and all sequences in which there is at most two words between ‘health’ and ‘education’:
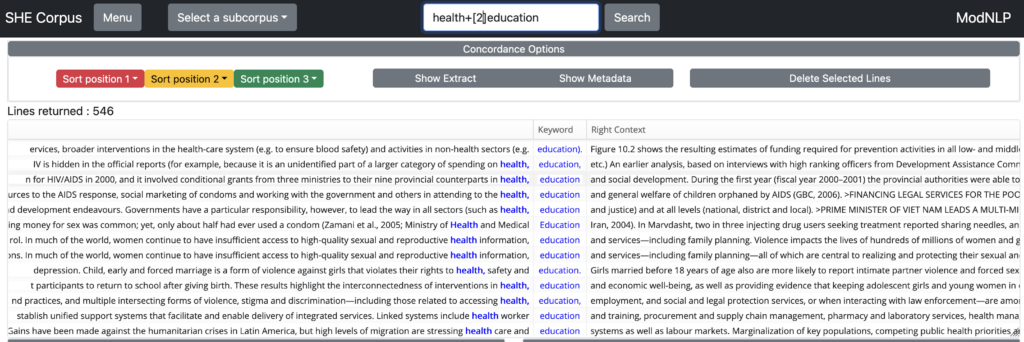
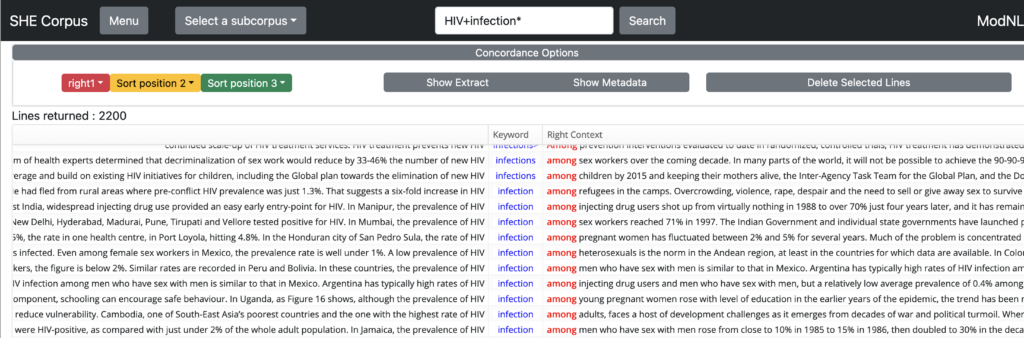
Combinations of words and wildcards are also allowed in sequences, so entering HIV+infection* will find …HIV infection as well as HIV infections.
Using sequences to find exact combinations of keywords is possible and wildcards can be used to find patterns with an exact number of intervening words. However, these queries will take longer to run.
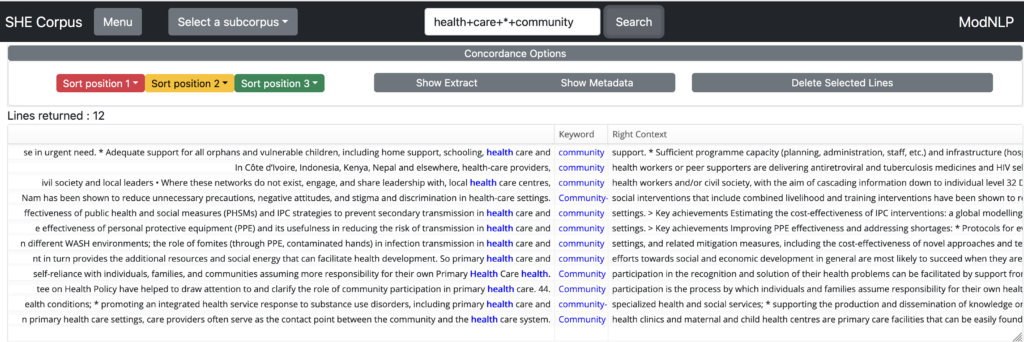
An example query of health+care+*+community finds the concordance lines shown below.
OR Operator
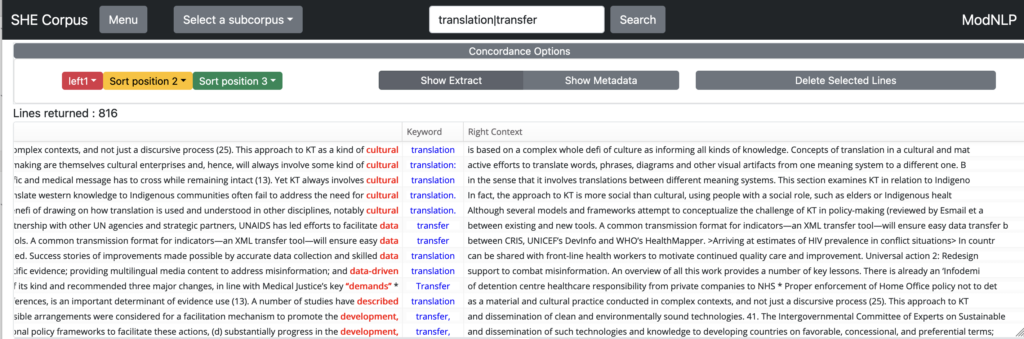
You can search for alternatives by using the OR connector |. For example, searching for translation|transfer returns concordances for both items.
Regular expressions
Finally, searching using ‘regular expressions’ allows you to select any string that matches a specified element of regular language. Regular expressions need to be enclosed in double quotation symbols (e.g. “regex”). Be careful not to mix regular expressions with the basic search syntax for alternatives and sequences detailed above, and to only place double quotations around the part of your query that contains the regular expression. A selection of example ‘regex’ searches are shown below:
- “(man|men)” retrieves a concordance of lines containing EITHER man OR men (i.e. the vertical bar is used to separate alternatives; the set of alternatives must be placed within parentheses);
- democracy+”(is|as|means)” retrieves a concordance of sequences containing democracy AND EITHER is OR as OR means;
- “labou?r” retrieves a concordance of labour AND labor (i.e. the question mark is used to indicate that the ‘u’ in this search string is optional);
- “citizens?(hip)?” finds instances of citizen, optionally followed by an ‘s’ AND optionally followed by ‘hip’ (i.e. the parentheses group the characters in ‘hip’ together as a suffix that can be treated as optional. This regex can thus be used to generate a concordance of citizen AND citizens AND citizenship);
- “pl…” retrieves a concordance of all five-letter words beginning with ‘pl’ contained in the corpus (i.e. the full stop is used here to indicate any single character, not including white space).
- “dem.{2,7}” returns a concordance of all words starting with ‘dem’ followed by a minimum of two characters and a maximum of seven characters (i.e. the curly braces {} are used in combination with the full stop to indicate a minimum and maximum number of characters {min,max}).
- “well-?being” returns a concordance of both wellbeing and well-being. Thus, you can capture spelling variants: “risk-?taking” returns both risktaking and risk-taking, which are essentially variants of the same word.
Note that you cannot always copy a regular expression from the above list and paste it into the search box. You must type it in. A brief guide to regular expression syntax is also available here.
Numerals
In the SHE Corpus (but not the Genealogies corpus, which is available via the same interface), the indexer has been configured to index numerals (e.g. 1, 2, 300, …) as well as words. You can therefore search for sequences. For example, if you are interested in capturing all instances of the 90-90-90 target to end the AIDS epidemic, you can enter 90-90-90 in the search box.
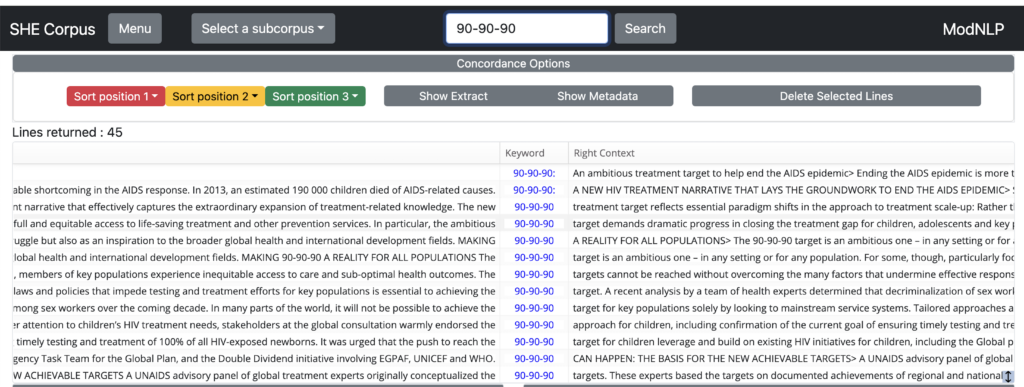
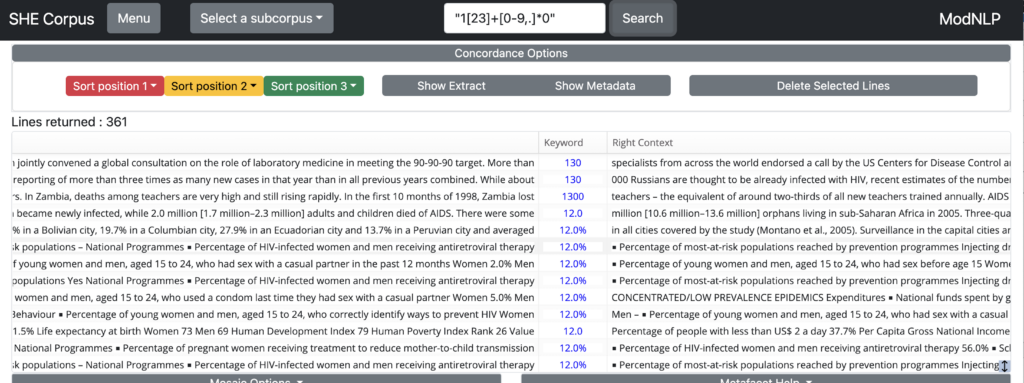
Regular expressions can also be used to search for strings denoting numbers. Entering “1[23]+[0-9,.]*0” (note the double quotes indicating a regular expression query) will retrieve all numerals starting with 1, followed by one or more times 2 or 3, optionally followed by any number of numerals (from 0 to 9) or ‘,’, or ‘.’, and ending in 0. So this regex search would retrieve, for instance, 12,000. 12.0, 12.10, 12.50, 13280, etc.
Sort
Searched concordances can be sorted at a position relative to the keyword, as indicated by the sort buttons in the top lefthand corner of the concordance.

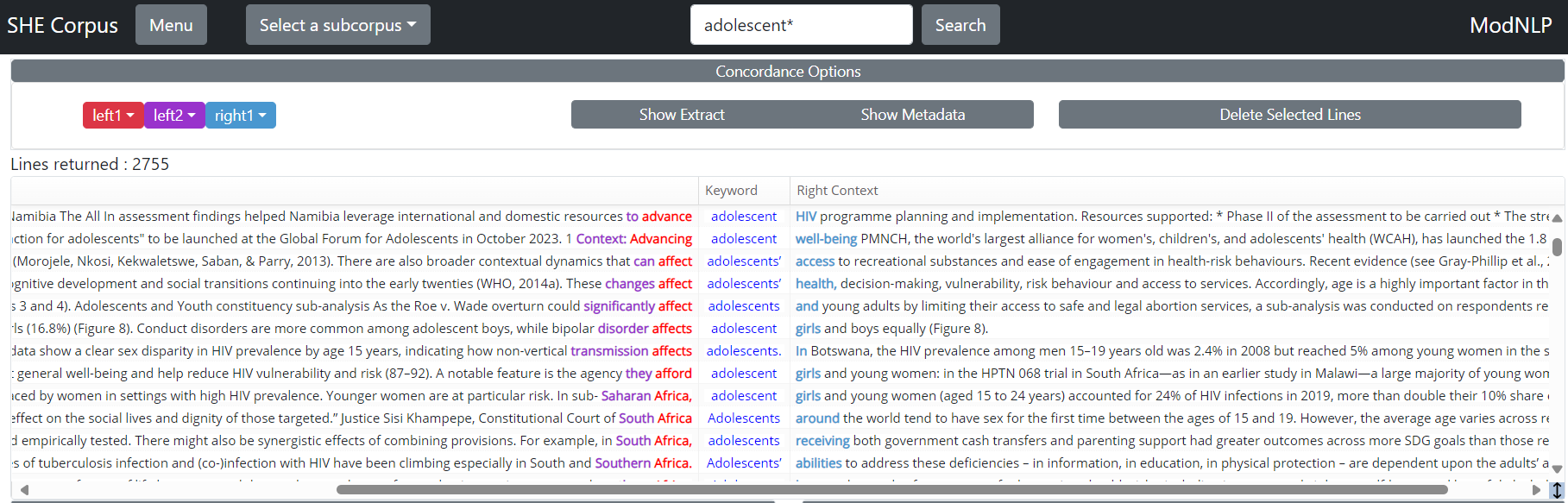
Select one or more of the three sort positions using the dropdown menus for either the right or left context. The words at the sorted position(s) will be highlighted and the sort buttons will indicate the selections made. The concordance of adolescent* below is sorted by first position to the left, then second position to the left, and finally first position to the right of the keyword.
If you use a wildcard you may find it useful to sort concordances by ‘Keyword’ in order to see each variant (e.g. adolescent and adolescents) in one block. This can be done by selecting ‘keyword’ in the first sort position.
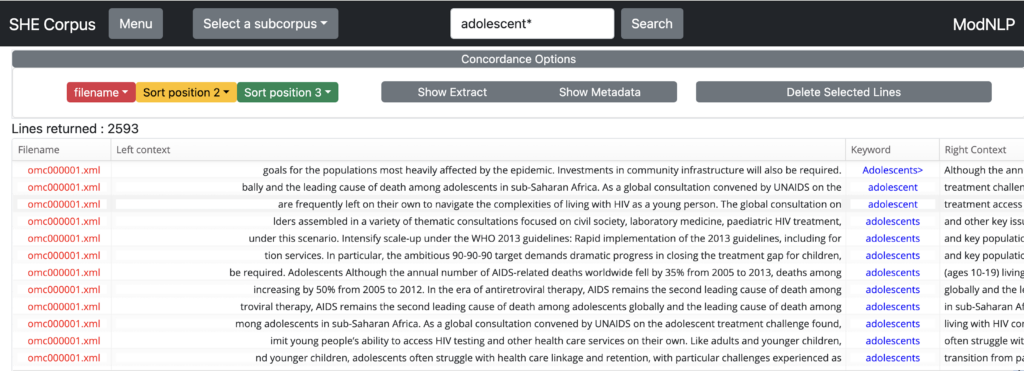
You can also sort by ‘Filename’, in order to group concordance lines according to the different texts from which they have been extracted.
Extract
Clicking on a concordance line and then on the ‘Extract’ button will bring up a window containing an expanded context for that concordance line, as shown below:
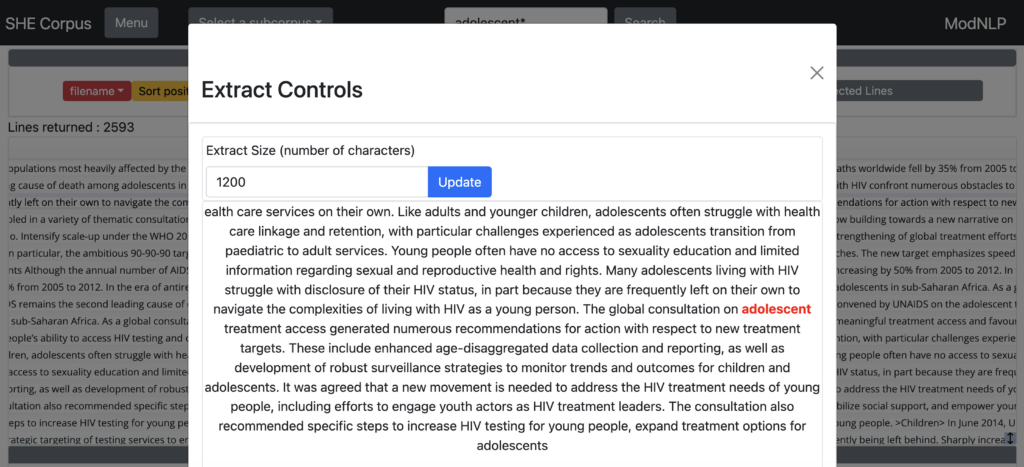
The default size of the extract is 300 characters, but you can expand it by changing the numeral in the box and clicking ‘Update’. Due to copyright restrictions, the maximum number of characters you can enter in the box is 1200.
Metadata
Clicking on a concordance line and then pressing the ‘Metadata’ button will bring up a window containing metadata for the file which contains that concordance line, as shown below:

For corpora that include classification of visuals, such as the SHE Corpus, selecting a concordance line and clicking on the Metadata button will display the Metadata window, including all visuals (images, tables, pictures etc) per document section and their categorisation according to SHE’s taxonomy of visuals, which is based on a taxonomy proposed by Desnoyers (2011).
Desnoyers L. Toward a taxonomy of visuals in science communication. Technical Communication. 2011, May 7; 58(2): 119-34.
Scroll down to see more visuals.

Delete Line(s)
Selecting a concordance line and then clicking on the ‘Delete Selected Lines’ button will remove this line from the concordance. You can also select and delete a block of consecutive lines – SHIFT+OPTION on Apple Mac, CTRL+SHIFT on Windows. This can be a useful feature if you wish to declutter the display in order to focus in on a particular collocation or set of collocations. The counter at the top lefthand corner of the concordance will change as you delete lines.
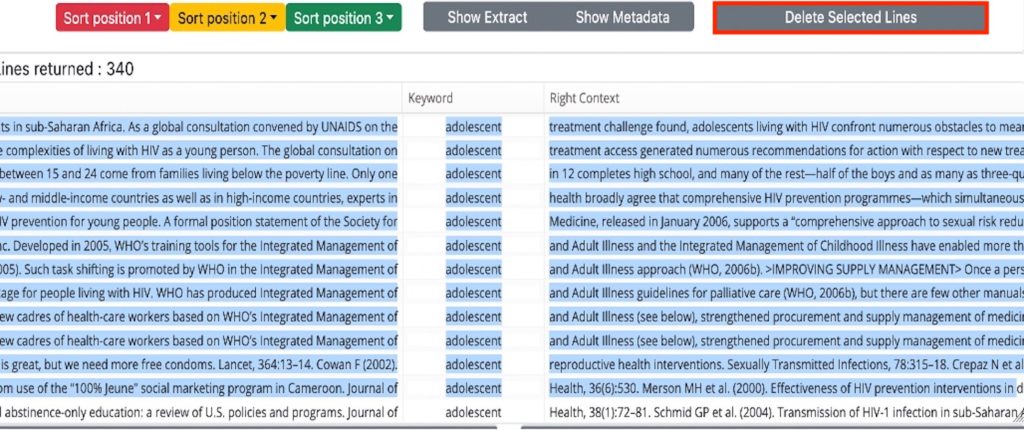
Running the same search again will bring any deleted lines back into the concordance displayed.Menu
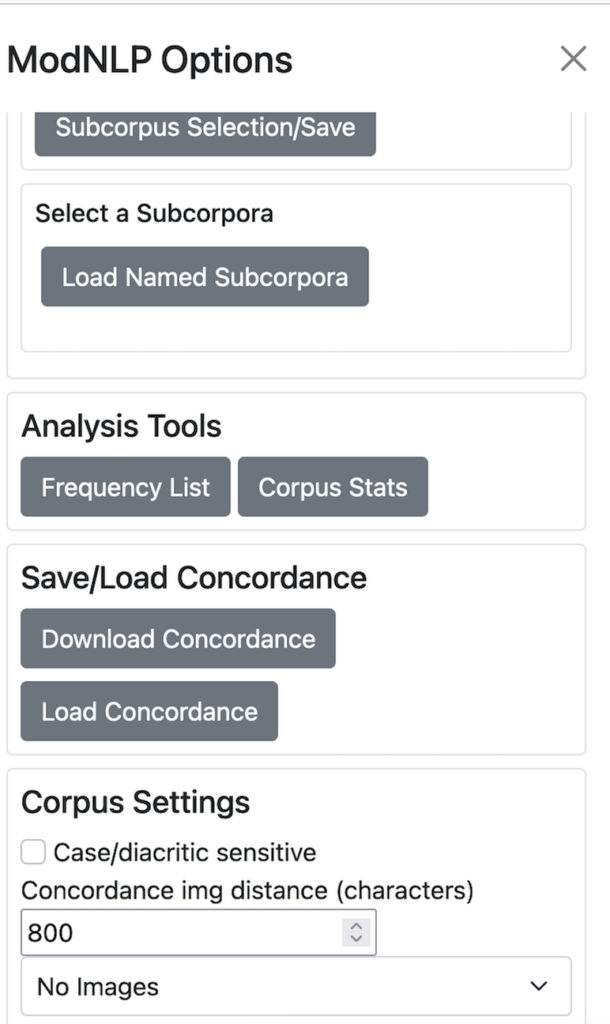
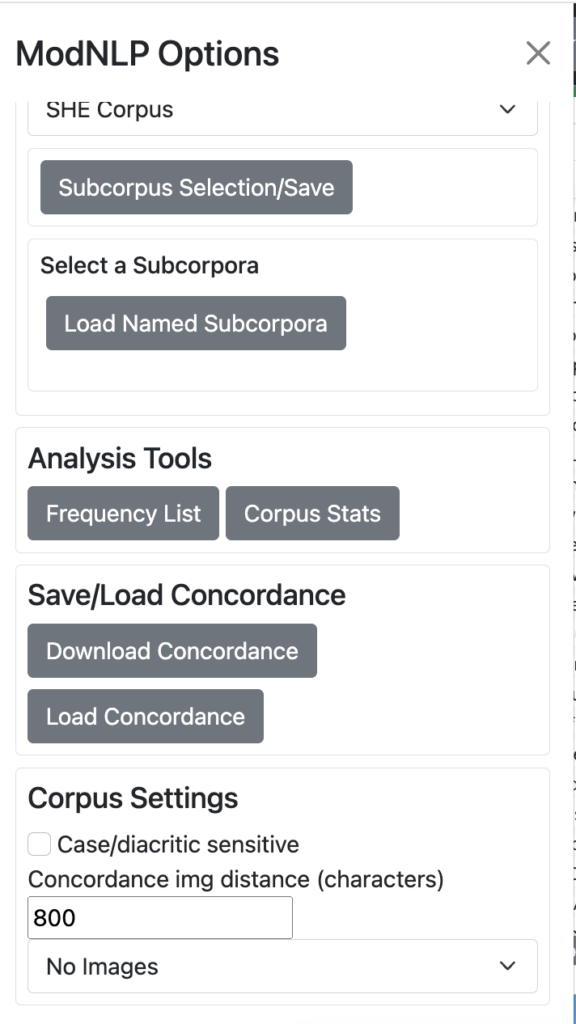
Click on Menu in the top lefthand corner of the screen to access a range of software tools and options.
These are organised under four headings: Subcorpus Selection/Save Tools, Load Named Subcorpora, Analysis Tools (Frequency List and Corpus Stats), a Save/Load Concordance function, Save/Load Concordance (Download Concordance and Load Concordance), and Corpus Settings.
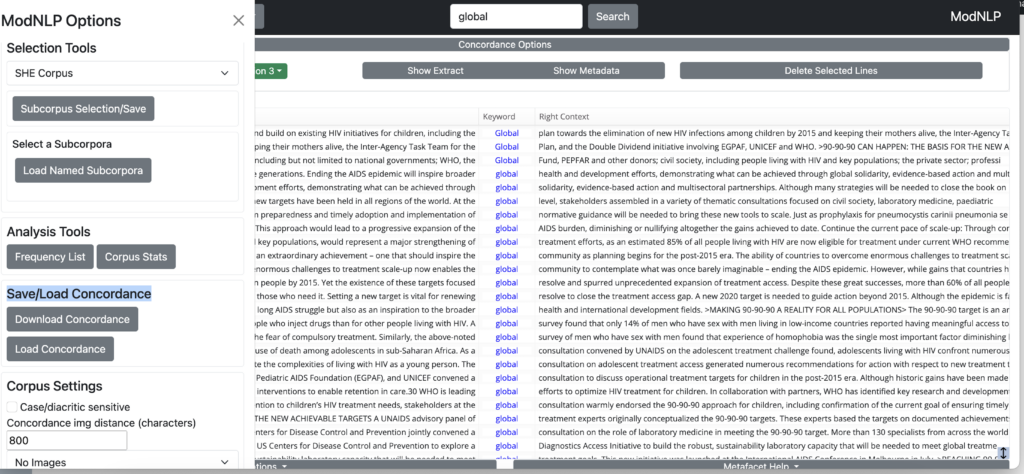
You can switch between SHE Corpus and GoK English at the top of the corpus selection box. The default is SHE Corpus.
Selection Tools: Corpus Selection
-
The corpus selection tool allows you to restrict the results of concordance queries and the contents of frequency tables to files matching certain criteria. These criteria can be, for example, their publication date, a specific organisation such as UNAIDS, or a journal such as The Lancet. Click on Corpus Selection to access the range of choices you can select from.
- Please note that the first thing you should select is the language you want to work with. If you do not select either English or Spanish, your queries will potentially retrieve data in both languages, which is not useful for most applications.

The menu boxes allow you to select one or more parameters for texts to be included in or excluded from the desired subcorpus. Scroll to the right within a box to see more of the text, e.g. the full name of an organisation or journal. Scroll down to see more options. In order to select more than one item (e.g. a range of dates) within a single menu box, hold the CTRL key on your keyboard (COMMAND on Apple computers) as you click on each.
Criteria in multiple menu boxes can also be connected to form the logical expressions which ultimately determine what gets included or excluded. You can, for example, choose a subcorpus of declarations published by the UN between 1987 and 1999 by selecting each of these criteria in the interface and clicking ‘Save Selection’ at the bottom of the screen:

By default, selecting an item in the menu boxes will include files that meet this criterion in the subcorpus. To exclude certain texts from your subcorpus selection, select the relevant criterion and tick the ‘Exclude’ checkbox below the relevant menu.
For example, if you want to run a search on only the draft resolutions contained in the corpus (i.e. no final resolutions or journal articles, etc.), you should select ‘draft resolution’ in the ‘Format’ menu box. This will include only those texts that have been tagged as draft resolutions in their metadata within your subcorpus selection. If, on the other hand, you want to run a search on all dates of publication except the 1990s, you should instead select all 1990 dates in the ‘Pub date’ menu box and tick the ‘Exclude’ checkbox below this menu.
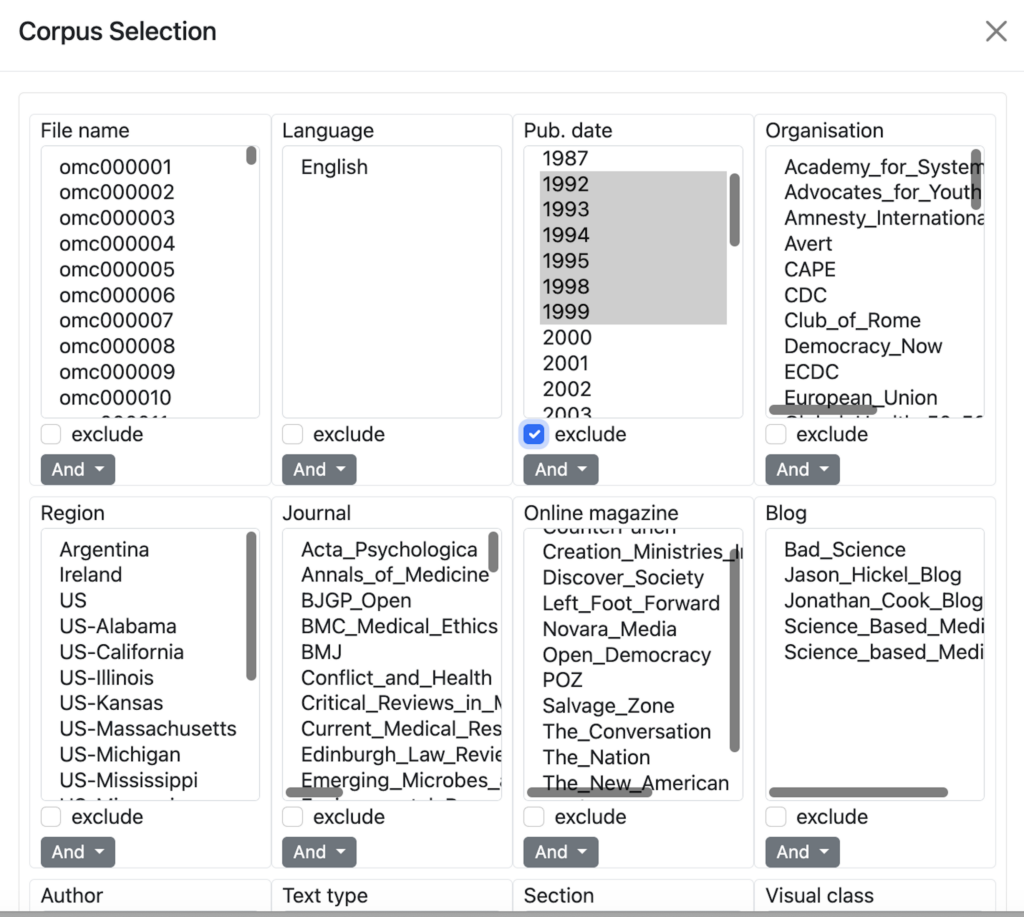
Click ‘Save Selection’ at the bottom of the screen to activate your selected search. Click ‘Clear’ to deactivate it.
Sometimes the information in the metadata will not be sufficient to define the required subcorpus. In this case, you can build the subcorpus manually by selecting the required filenames individually and saving them to a named subcorpus that you can activate whenever you need to.
For example, you might be interested in a specific set of publications, on a particular topic, and you might want to be able to work with the same selection again in future sessions. To do so, select the appropriate filenames, scroll down to the bottom of the corpus selection window, enter a name for your selected corpus in the box on the left, and click on Save Named Subcorpus to File.

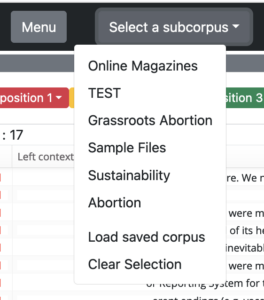
To select a named subcorpus click on Select a Subcorpus at the top of the screen and make a selection. To clear your selection, click on Clear Selection in the same menu.
Note: To access a list of all files in the corpus, with basic information on titles, authors, organisations, journals and dates of publication, together with url links where available, click on Contents of the SHE Corpus on the SHE Corpus website.
Contents of the Sustainability & Health CorpusSave/Load Concordance
SHE is an open-ended corpus that grows continuously as more texts are added to it. This means that the concordance output you generate may be different next time you redo the search. The Save/Load Concordance function allows you to save a concordance, load it at a later time, and analyse it using all the sort functions and analysis tools available (Mosaic and Metafacet).
To save a concordance you generated, click on Download Concordance:

The concordance will be saved on your computer in .txt format.
To reload the concordance at a later time, click Load Concordance and select the file on your computer.
Analysis Tools
Several analysis tools have been developed to enhance corpus analysis. These tools are mature prototypes and as such are under continued development. See also Mosaic Visualisation and Metafacet Visualisation below.
Frequency List
The Frequency List tool can be accessed by clicking the MENU button at the top lefthand corner of the screen.
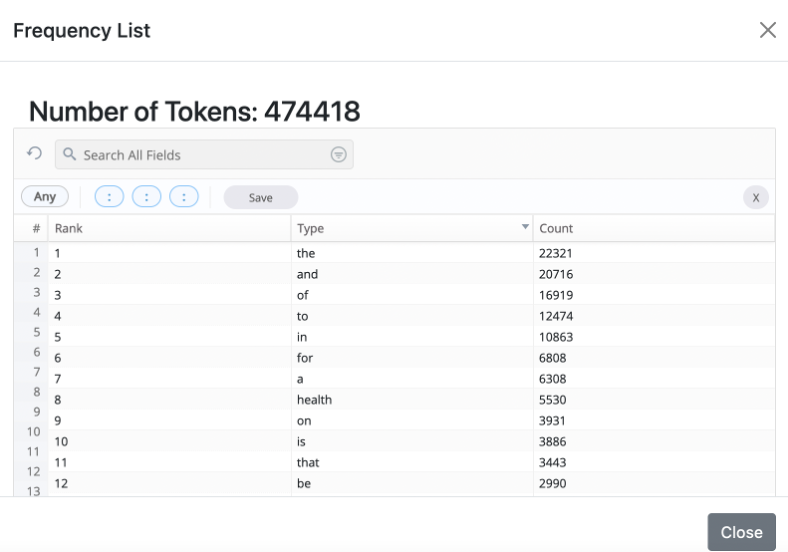
Clicking on Frequency List will generate a list of all tokens in the corpus with their respective frequencies. This may take a little time, depending on the size of the corpus.
The overall number of tokens in the corpus is displayed at the top. The default order of the list is by most to least frequent.
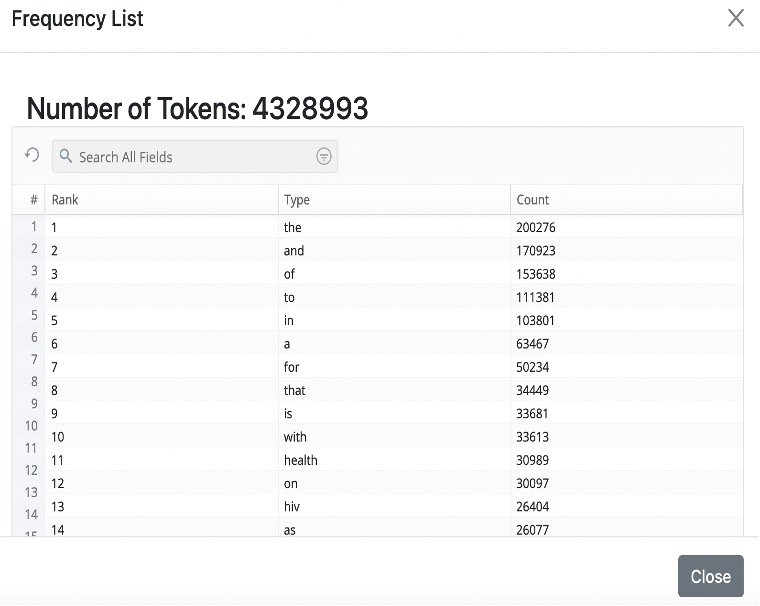
Click on Rank to reorder the list by least to most frequent tokens.
Click on Type to reorder the list alphabetically.
Click on Type again to reverse the alphabetical order. This will display a variety of foreign words and technical symbols at the top, followed by tokens beginning with z:
You can also retrieve the frequency and rank of a particular word by entering it in the search box at the top.
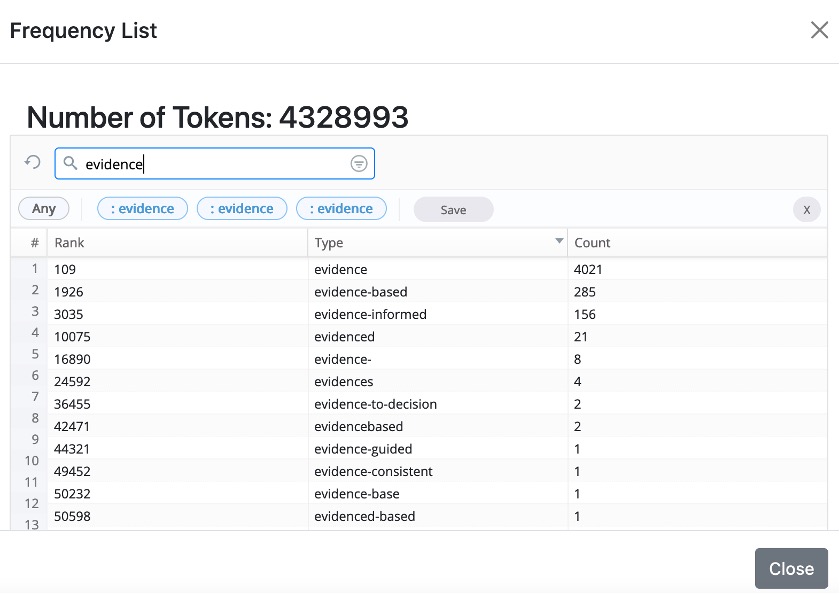
Click on Download in the top righthand corner to download a frequency list you generated as a .csv file.
The Frequency List tool generates a list of all tokens in the corpus by default. If you select a subcorpus through the Corpus Selection interface the list will display only the tokens in this selection. The overall number of tokens at the top will reflect this.
For example, if you select WHO from the list of organizations in the Corpus Selection interface and then click Frequency List, you will see only the tokens that appear in WHO documents, with their relevant frequencies.
Corpus Stats
The Corpus Stats tool can be accessed by clicking the MENU button at the top lefthand corner of the screen. It appears next to the Frequency List button.
Clicking on Corpus Stats will generate a view of the distribution of the full contents of the corpus across a set of attributes, including Language, Format, Publication Date, Organisation, Journal, Online Magazine, Blog and Region (for the SHE Corpus), and relevant attributes for the GoK Corpus.
There are two selection buttons at the top of the Corpus Stats menu: linear/log view, and Files/tokens. Hovering over any item will show the statistics associated with it.

The Corpus Stats tool generates a view of the distribution of attributes in the full corpus by default. If you select a subcorpus through the Corpus Selection interface the tool will generate a view of the distribution of attributes in this selection only.
Corpus Settings
The Corpus Settings option can be accessed by clicking the MENU button at the top lefthand corner of the screen.
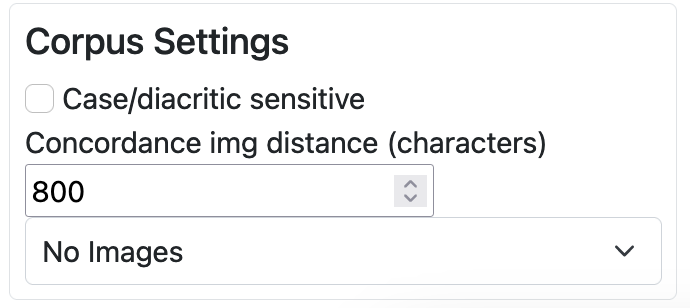
The first choice is between case/diacritic sensitive and case/diacritic insensitive output. The search function is by default not case-sensitive so a search for ‘WHO’ will retrieve both WHO and the pronoun who. In order to make a search case-sensitive, click ‘Case/diacritic sensitive’ to activate this option. The same applies to tokens with or without diacritics. The default option is to retrieve both forms; clicking on ‘Case/diacritic sensitive’ will return lines containing only the accented form of the search word.
The second choice concerns the display of images that accompany each text. The default is No images. Select Images to display the images accompanying a given keyword in the concordance line. Hover over an image to enlarge it.

Mosaic Visualization
The Mosaic visualization tool appears at the bottom lefthand side of the main page of the interface by default. You can enlarge or reduce it in size by grabbing the handle at the bottom righthand corner and moving it up or down. The handle will look different on different browsers. In Chrome it looks like a double-edged arrow.
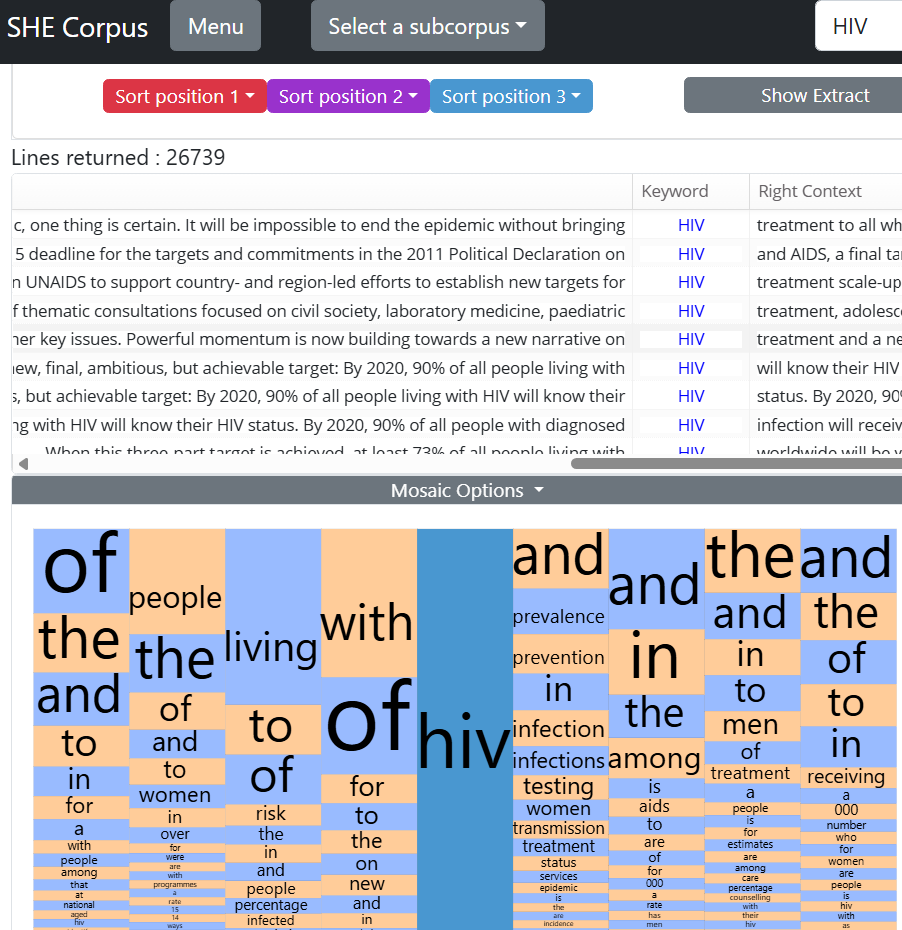
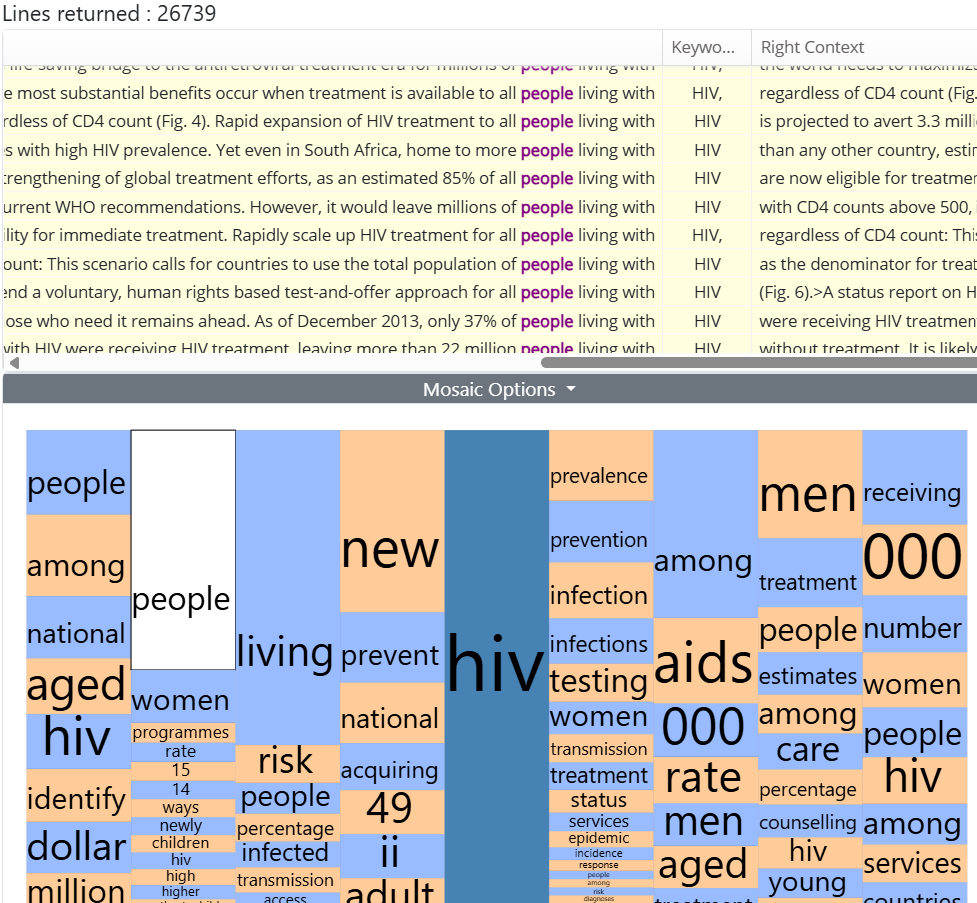
Unlike the Frequency List, the Mosaic generates positional word statistics based on a concordance you have already generated, and interacts with the concordance to highlight any selections you make.
The default view shows all tokens that appear 4 positions to the left and 4 positions to the right of your search word. Each box (tile) represents a different word at each position. The height of each box is directly proportional to its frequency.
For example, the Mosaic above is generated by a concordance of HIV. Looking at the visualisation it should be clear that:
- ‘with’ is the most frequent word one position to the left of HIV.
- ‘living’ is the most frequent word two positions to the left of HIV.
- ‘living with HIV’ is a strong pattern in the corpus.
The default view of the Mosaic retains all function words (like with, of, and, the), which are highly frequent in any corpus but do not carry much meaning. You can declutter the Mosaic view by clicking on Mosaic Options at the top and selecting Remove Stopwords.

The range slider which appears under the Remove Stopwords option filters out Mosaic tiles above and below the threshold frequencies indicated. Move the leftmost slider to the right to remove low-frequency collocates, which will make patterns involving high-frequency words more prominent. Move the right slider to the left to remove high-frequency collocates, which will make patterns involving low-frequency collocates easier to spot.
Click on Mosaic Options again to see more of the Mosaic and work with it.
Hovering over a tile with the mouse pointer will display the overall number of instances at this position (Count) and the percentage it represents of all tokens occurring at that position (Frequency).
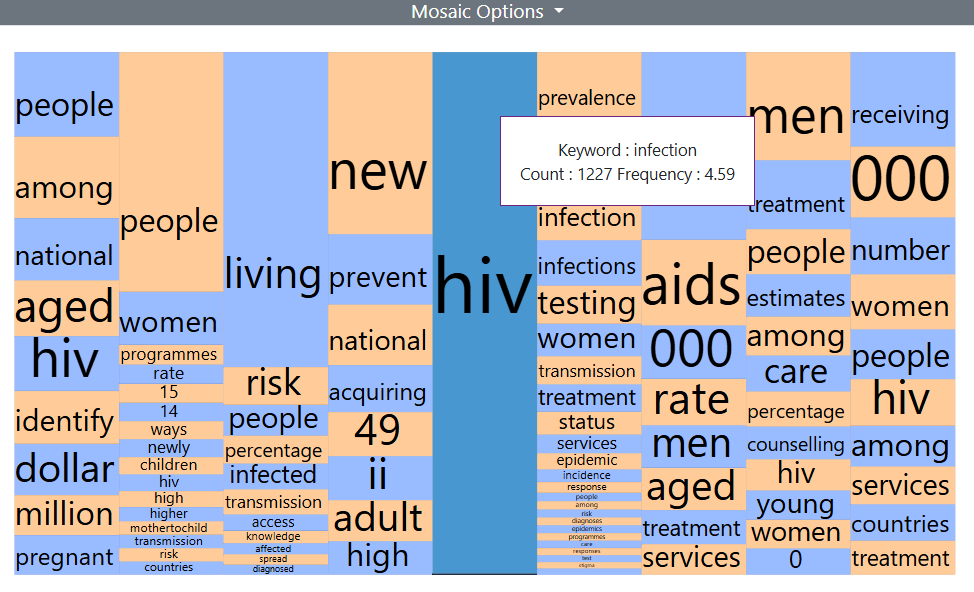
Mosaic Interactions
The Mosaic and the concordance window are linked and interactions with the Mosaic are mirrored in the concordance window. Clicking on a tile in the Mosaic sorts the appropriate column in the concordance window and scrolls to the clicked word where it appears in that position.
All concordance lines containing the clicked word in the relevant position are highlighted in yellow. In addition, the clicked word is also highlighted in the concordance where it occurs in the relevant position.
To remove items that create unnecessary noise or to home in on a particular set of items that are of interest, click on each tile you wish to remove, then SHIFT+CLICK to remove it. This is particularly useful when you wish to look more closely at several items that form a semantic group or are grammatical variants. As in the following version of the above Mosaic.

If you search using a wild card you may wish to remove some of the keywords generated. You can also do this by clicking on each keyword you wish to remove, then SHIFT+CLICK to remove it
Metafacet Visualization
The Metafacet window appears at the bottom righthand side of the main page of the interface by default. You can enlarge or reduce it in size by grabbing the handle at the bottom righthand corner and moving it up or down.
Once you have generated a concordance, this tool allows you to see the number of lines associated with a particular facet of the metadata, such as publication date or organisation, and to filter the concordance based on the attribute you selected. In the example below, the facet selected is ‘Organisation’.
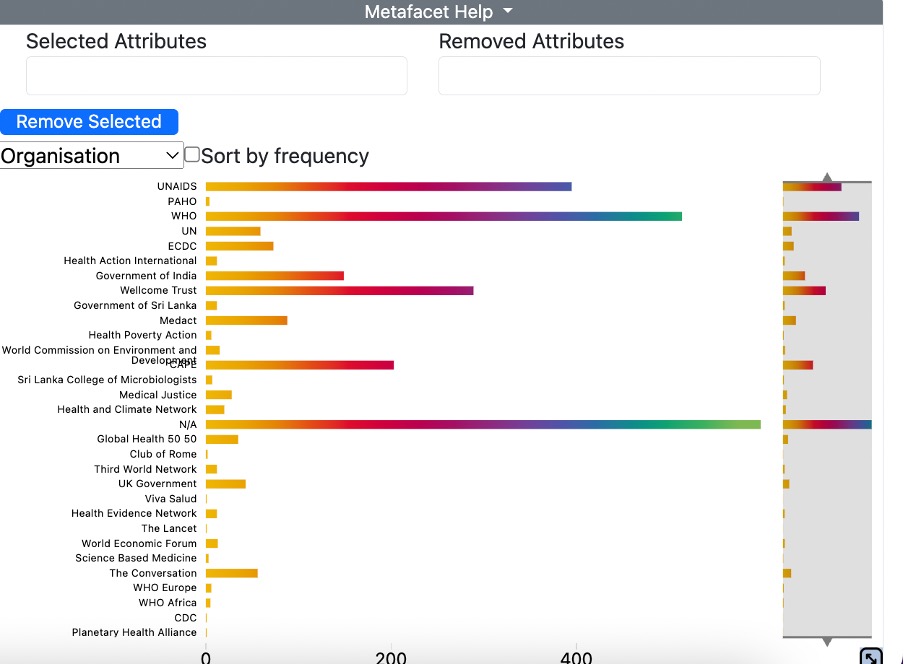
The options you can select from are displayed in a dropdown window at the top lefthand side of the window.
The list of elements displayed in the output of the visualisation is not ordered alphabetically but depends on the order in which the individual items happen to appear in the generated concordance – in the above example, the order reflects the fact that the first set of concordance lines generated come from UNAIDS, followed by PAHO, etc. The ‘Sort by frequency’ button allows you to reorder the display by the frequency of occurrence of the search term in a particular subset of files.
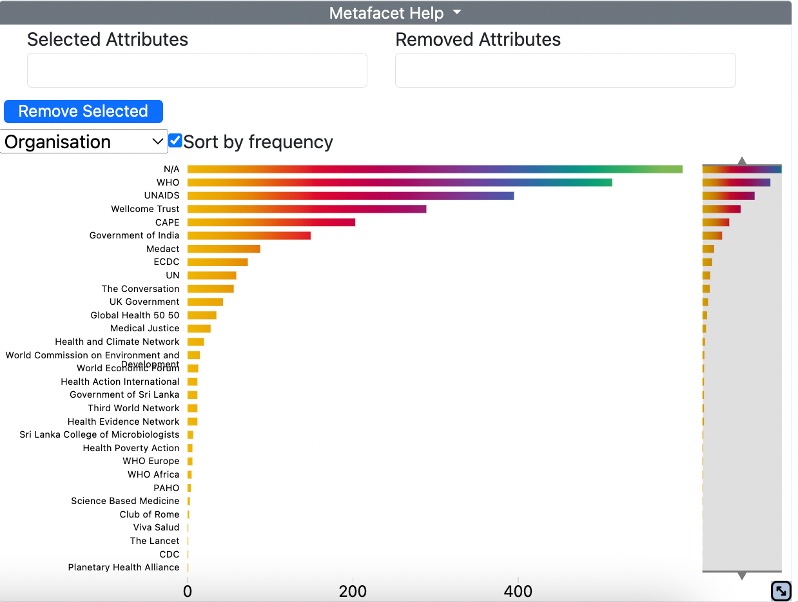
The information relevant to each attribute is often very dense and it will not always be easy to read the text on the left.

You can zoom in by manipulating the arrows at the top and bottom of the column on the righthand side. As you reduce the size of the window, the text will become clearer. In some cases, you have to reduce the window considerably at both ends in order to see the details of a very extended list:
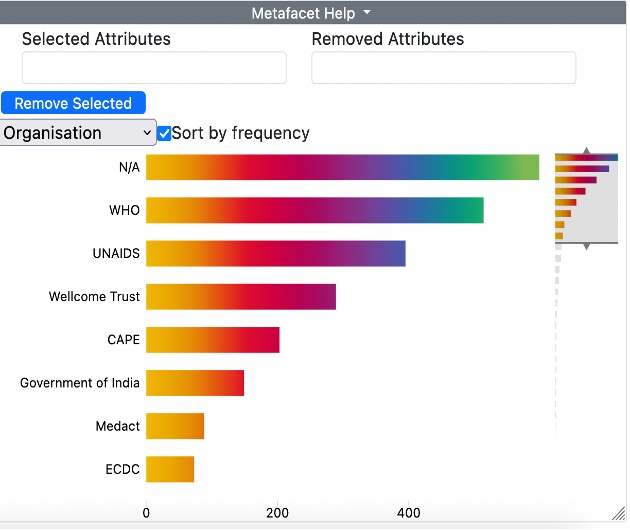
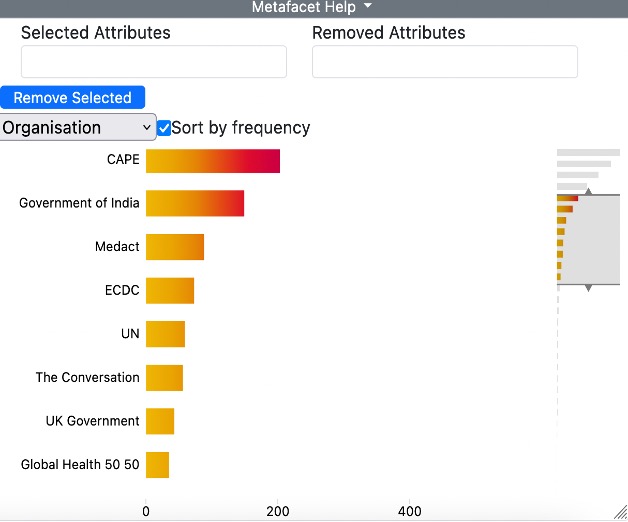
Once you have reduced it sufficiently, grab the middle of the righthand column and move it up and down to see all the elements in the list:
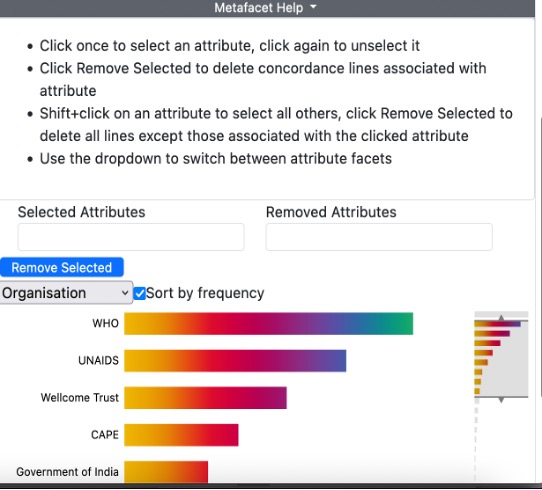
To access instructions on how to select or remove items from the lists of attributes, click on Metafacet Help at the top of the screen (and click again to close the help menu).
Any selections you make will appear in the window marked Selected Attributes, and any you remove will appear in the window marked Removed Attributes. You can select and remove attributes across multiple facets such as Organisation, Date, or Journal.
The Metafacet tool interacts with the concordance generated and with the Mosaic. The selections you make using both tools are reflected simultaneously.
If you click on Remove Selected, the lines associated with the attribute will be deleted from the concordance.
The concordance lines matching the selections you make will appear framed in red:
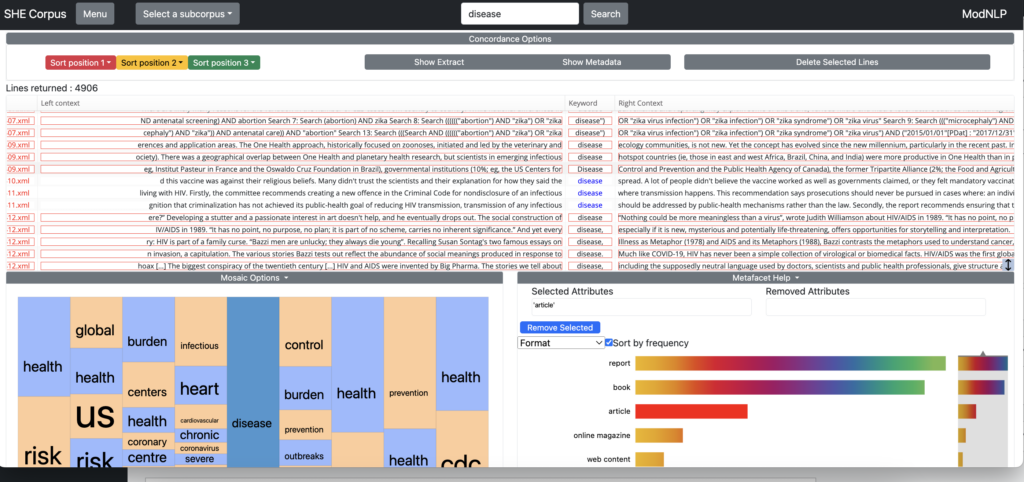
Unlike the Mosaic, the lines matching the selected attribute will not appear in a block but will be dispersed across the concordance.
The Metafacet selections you make will also be reflected in the Mosaic visualization. If you remove the attribute ECDC under Organisation, for instance, the range and frequencies of collocates displayed in the Mosaic will be adjusted accordingly.