
Table of contents
Aim
To produce a machine-readable version of the report, journal article or other item to be incorporated into the corpus. For each document to be added to the corpus, two files need to be created: a header file (.hed), with information about the document (metadata) and an .xml file with the text of the document itself.
Method
This involves a four-stage process:
- creating a header file in which to store metadata describing the text as a whole
- copy-and-pasting from the source document (typically a pdf) into MS Word to extract all and only written text. In the SHE Corpus visuals are downloaded and stored separately; see Visuals below
- annotating the text with XML to document its structure and component parts
- checking that the header and text files conform to the requirements of the software by validating them against the project’s two .dtd files.
Tools
The text editor Visual Studio Code is recommended for steps 1, 3 and 4 as this has all of the required functionalities. If you do not already have Visual Studio Code installed on your computer, it can be downloaded here for free: https://code.visualstudio.com/download
Setting up Visual Studio Code
(you only have to do this once: the software should remember these settings in subsequent sessions)
- On the left-hand bar: Select EXTENSIONS
- In the search bar, type XML Language Support by Red Hat and press Enter
- Choose this extension from the search results and click INSTALL
- Install the Error Lens extension using the same method
- On the top-menu bar: click VIEW and toggle on WORD WRAP
Setting up your workstation
- Create a new folder on your computer’s hard drive in which you will store the corpus text files and the files you will download in the next step.
- Download the latest versions of the OMCTEXT.DTD and OMCHEADER.DTD files, also available from the following link (in the DTD folder): https://gitlab.com/luzs/oslomedicalcorpus
- Use the download button to download the files or they will not work!
- Make sure that the OMCTEXT.DTD and OMCHEADER.DTD are stored in the same folder as your corpus files.
- These files may be updated from time to time as the project advances so it is worth downloading them from Gitlab regularly, before you start working on a new text. These files are used by Visual Studio Code to validate the XML corpus files. More specifically, Visual Studio Code uses the .dtds to check that the XML metadata tags which you have added to the corpus text files are consistent across all of the files in our corpus and that they have been used correctly.
- Create a new folder on your computer’s hard drive in which you will store the corpus text files.
- Make sure that the OMCTEXT.DTD and OMCHEADER.DTD files are also stored in this folder.
Creating a header file
- The text contained within the reports, journal articles etc. chosen for inclusion in our corpus will be placed in an .xml text file in Step 4 below. But before we do so, we need to first create a header (.hed) file. The header file provides all the metadata relevant to each corpus text: its date of publication, the name(s) of its author(s), its title, etc..
- To begin, in Visual Studio Code, click FILE > NEW and then save this new file as a .hed file using the filename you have been given (e.g. omc000083.hed – please note that all filenames in the corpus should begin with omc and then a 6-digit number).
- Paste the following template into this file.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<!DOCTYPE omcheader SYSTEM "omcheader.dtd">
<omcheader>
<document filename="" language="" publication_date="" capture_date="" format="" article_type="">
<title></title>
<author>Surname, First name</author>
<organisation name=""/>
<category>
<region description=""/>
</category>
<copyright status="">
<holder></holder>
</copyright>
<comments></comments>
<DOI></DOI>
<section id="s1" type="text"></section>
</document>
</omcheader>
| Important: Consult the latest .dtd, and read the information below on when to include which optional elements and attributes. Adapt the template accordingly. All XML metadata tags need to have two parts, one that opens them and one that closes them. A forward slash / is used to distinguish a closing tag from an opening tag (e.g. <title>…</title>). The only exceptions in the header files are the <organisation name> tag and the <section id> tag. |
- The metadata is included in the form of elements or attributes.
Elements are contained between opening and closing XML tags. For example, title and author are elements: <title> This is a Title </title>
Attributes are contained within quotation marks within the XML tag itself. For example, the filename is an attribute of the document element: <document filename=”omc000001″ publication_date=”2014″> …. </document>
- Insert relevant information in each field, either between the quotation marks (in the case of attributes) or between the appropriate XML tags (in the case of elements), as in the following example:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<!DOCTYPE omcheader SYSTEM "omcheader.dtd">
<omcheader> <document filename="omc000550" publication_date="2023" capture_date="2023" format="online_magazine" online_magazine="Truthout">
<title>Alabama GOP Bill Aims to Charge People Who Get an Abortion With Murder</title>
<author>Walker, Chris</author>
<category>
<region description="US-Alabama"/>
</category>
<copyright status="creative_commons">
<holder>Truthout</holder>
</copyright>
<comments>CC BY-NC-ND 4.0</comments>
<visual_copyright> Photo credits: Getty Images</visual_copyright>
<section id='s1' type="text">
<visual pos='349'>
<img src="omc000550-figure-1.png"/>
<caption>The exterior of a state government building in Montgomery, the capital city of Alabama</caption>
<taxon class="cosmogram" order="reigram" family="reigramfamily" qualifier="descriptive"></taxon>
</visual>
</section>
</document>
</omcheader>
- More information on the annotation of visuals is provided below.
- Some fields (whether elements or attributes) in the header are optional as they only apply to certain kinds of text in the SHE. These fields should be deleted from the finished header if they are not needed. They include:
- source: This is the archive/distribution site or repository of preprints of articles that are yet to undergo peer review, e.g. medRxiv, bioRxiv and arXiv. These are not journals (e.g. they have no impact factor) nor bibliographic databases.
Note that source is only relevant for preprints of journal articles downloaded from these repositories
-
- Document format: although optional, if included you can only choose from one of the available options in the .dtd (the list below is incomplete and new formats are added as needed – it is used for illustrative purposes only):
amicus_brief|article|bill|blog|book|charter|constitution|convention|declaration|draft_resolution|judgement_opinion|manual|online_magazine|oral_argument|parliamentary_debate|report|resolution|response|social_media|speech_official_statement|textbook|web_content|wiki
If you choose online_magazine, you should add the name of the magazine. And similarly if you choose blog. For example:
<document filename=”omc000254″ publication_date=”2022″ capture_date=”2022″ format=”blog” blog=”Science-Based Medicine”>
OR
<document filename=”omc000255″ publication_date=”2022″ capture_date=”2022″ format=”online_magazine” online_magazine=”The Conversation”>
Note: Always check the latest version of the .dtd for the actual list to choose from.
Note: Some organisations, like Creative Ministries International, publish a range of different document formats, including an online magazine or blog. In this case, the name of the organisation should appear in the organisation field, and the format should be recorded as online magazine or blog, with the specific title of the magazine or blog stated. For example:
<document filename=”omc000255″ publication_date=”2022″ capture_date=”2022″ format=”online_magazine” online_magazine=”Creation_Magazine”><organisation name=”Creative_Ministries_International”/>
-
- article_type: for all journal content, the document format will be ‘article’ and you will then need to specify the article_type, as determined by the DTD, which currently lists:
research|review|opinion|editorial
Research: covers any type of article published as such in a journal.
Review: covers all types of review (systematic, meta, scoping). Reviews are explicitly classified as such in medical journals, with the word ‘review’ included in the title and/or abstract.
Note: The Lancet Commissions are to be tagged as ‘Review’.
Opinion: covers any critical or explanatory note written to discuss, support, or dispute an article or other presentation previously published. It appears in publications under a variety of names: opinion, comment, commentary, viewpoint, perspective, etc.
Note: Items published as NSeries in The Lancet should be tagged as ‘Opinion’.
Editorial (or editorial comment): consists of a statement of the opinions, beliefs, and policy of the editor or publisher of a journal, usually on current matters of medical or scientific significance to the medical community or society at large. Editorials are clearly labelled as such in all journals.
-
- organisation You can enter more than one organisation but you can only choose from a prexisting list specified in the OMCHEADER.DTD (remember to download the latest version of this from GitLab). The following list thus only gives some examples:
WHO|WHO_Africa|WHO_Americas|WHO_Europe|WHO_Asia|WHO_Mediterranean|WHO_Pacific|UN|UNAIDS|PAHO|CDC|ECDC
|
Important: In the case of journals such as The Lancet or BMJ, leave the organisation field blank and delete the tag. Similarly for online magazines such as Counterpunch and The Conversation. In the case of books, record the publisher (e.g. Cambridge University Press) as the organisation. Note: Some organisations, including publishers such as Verso and networks such as Creation Ministries International, publish articles in a blog section or an online magazine on their websites, in addition to other web content and documents that may be included in the corpus. If you are creating a header for a blog piece or magazine article from these sources (rather than general web content), enter the name of the publisher/institution/collective etc. under organisation and either blog or online_magazine under document format, so that you can also specify the name of the relevant blog or magazine. |
- category: this pertains to regions cited in the document and is currently only relevant to the MEDRA project. Select from three main options: Argentina, Ireland and the US. For the US, where relevant indicate specific states such as New York or Kentucky, as specified in Baserow. As with organisation, you can enter more than one region but you can only choose from the options listed in the .dtd. You can enter more than one region, as follows:
- Note that under publication date and capture date you should just include the year (not the month and day). Exact dates for e.g. blog articles may be noted in the comments field. Capture date is the year during which you or some member of the team downloaded the document from the web. It is recorded because online material is often edited, sometimes extensively, on an ongoing basis.
- Make sure there is no empty space after the year or filename, otherwise the software interface will recognize the year and the same year with a space following as two different publication dates. The same applies to filenames.
- If the author is an organisation, enter the name of the organisation in the author field as well as the organisation field.
- In cases where you want to add more than one name (e.g. for authors or translators) just duplicate the line that signals this section. For example, a report with one author would look like this:
<author>Zimmern, Helen</author>
Whereas a report with two authors will look like this:
<author>Zimmern, Helen</author><author>Smith, Alice</auhtor>
- Similarly, if you need to include more than one organisation, just duplicate the corresponding tag:
<organisation name="UNAIDS"/><organisation name="PAHO"/>
- If more than five people are listed as authors (e.g. for a journal article), please only include details of the first five authors, plus the last author listed (who is normally also an important contributor e.g. the head of the research group). Make a note of having done this in the comments field.
- CDC, WHO, UNAIDS etc. should be recorded as author or organisation (or both), depending on whether the document in question features named authors. If the latter, the relevant individual(s) should be listed as author(s) and WHO, etc. as organisation.
- Note that acronyms should be used in the author name field for organisations such as the WHO and UNAIDS, rather than the full name (*World Health Organization)
- The names of journals, online magazines and blogs should not be recorded in the Organisation field but only under document format (see below).
- If the document is a collected volume or report in which different sections are written by different authors, place the editors’ names in the <author> field and use the <comments> field to note that this is an edited volume or report consisting of sections written by different authors (rather than a multi-authored report). You should also list the names of all authors and titles of relevant chapters/sections in the comments field.
-
- online magazine, e.g. The Advocate, Politico, POZ Magazine. As with other elements/attributes above, you will need to choose from a predetermined list in the .dtd
- translation: to be used only when the text you are preparing is a translation, and then further elements need to be added, as specified below.
- comments: this is information that may be relevant but does not fit into any of the above fields, or notes on any uncertainty worth recording. Relevant information appearing at the end of an article, e.g. “This story has been updated to correct the proportion of women enrolled in college in 1970 and 1980” may be included in this section. Additional items of information should be placed together within the same tag, e.g. <comments>CC-BY, This story has been updated to correct the proportion of women enrolled in college in 1970 and 1980</comments. Otherwise the file will not validate.
- DOI: If available.
Translations
- If the text you are preparing is a translation of a document in another language, you will need to add the following lines after all the above metadata and complete the relevant fields accordingly:
<translation> <translator> <firstname></firstname> <lastname></lastname> </translator> <source language=""></source></translation>
Validation
The last step of this process of creating the header file is to check that your file validates against the OMCHEADER.DTD (double-check that this has indeed been saved in the same folder as the file on which you are working). To do this, click the errors icon in the very bottom left hand corner of the interface. If the file contains an error, you will see a validation error message, as below:
- Clicking on these error messages will direct you to the location of the error in the file. The most common errors are generated by typos (misspelling in an XML tag) or a failure to include a closing tag.
- Having resolved the error, save the file and continue the validation process until you receive no further error messages.
Creating the text file
- To create the text file you will first need to extract all of the written text out of the original document (e.g. the PDF file). This is most easily achieved by selecting all of the text in the document (CTRL + A in Windows), copying this to the clipboard and then pasting it into a Microsoft Word document. Save this Word document in the same folder on your workstation as a .doc file.
- Make sure the text in the .doc file corresponds accurately to the content of the original and that nothing has been left out. Make sure that spell check is activated and that you check all the underlined words/phrases. Always check against the original document, if in doubt.
- Make sure you correct all ligatures, which should be captured by the spell checker in Word, but retain them where they feature in the original spelling of a word (for example æ and œ).
- Remove all text and visuals that appear on the front and backcover of reports, books, and similar genres.
- Remove the copyright information that is often included at the beginning of reports and other publications, together with Tables of Contents and acknowledgements. For books, you should also remove the bibliography at the end and any suggested reading or references included at the end of chapters.
- If the text (other than books) includes a bibliography section at the end of the article, this should be kept. It will be placed in a new section (as noted below). Note that bibliographies are sometimes titled ‘Endnotes’ but they should nevertheless be included in a separate section (type=’references’).
- Endnotes in all genres should be omitted, (except where a bibliography is titled ‘Endnotes’, in which case it should be retained and included in a separate section, as noted in previous bullet point). Bibliographic references in books should be omitted.
- Footnotes in all genres should be omitted, except for in legal documents, where footnotes containing at least one sentence of full text will be retained, and placed directly after the relevant sentence in the body of the text. Shorter footnotes should be omitted.
- Remove all footnote and endnote numbers in the text.
- Retain abbreviation lists and glossaries but save them as visuals (not text); see section on Visuals below.
- For journal articles, omit ‘corresponding author’, ‘cite this article’, etc. Only the main text is to be included.
- Use the spelling and grammar check in Word to delete end of line hyphens (usually appearing as hyphen followed by space), making sure you do not delete hyphens in compounds such as ‘evidence-based’ and ‘pregnancy-related’, where the hyphen may also be followed by a stray space (make sure you delete the stray space in these compounds if present). The spell checker in Word is generally good at flagging this type of mistake and ignores normally hyphenated words.
- When you have made sure that all the relevant information from the original document (e.g. PDF file) is included in the .doc file, re-save the document as a plain text file (.txt) by going to FILE > SAVE AS and choosing the plain text file option from the dropdown menu. After you click Save, a dialogue box will open asking how you want to convert the document. Select ‘Other Encoding’ and choose ‘Unicode (UTF-8)’ from the menu.
- Again, make sure to save all of your files in the same folder.
- Next, launch Visual Studio Code and open the .txt file.
- At the very top of the text (line 1), insert the following:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><!DOCTYPE omctext SYSTEM "omctext.dtd">
<omctext>
<document>
<title></title>
- At the very end of the text, insert the following:
</document></omctext>
- Re-save the document as an xml file with the correct filename by saving it as e.g. omc000001.xml (again, in the same folder on your machine as the DTDs).
- Use the Find and Replace function of Visual Studio Code (CTRL + F) to remove any recurring but unwanted text such as headers, footers or page numbers. These can often be removed semi-automatically using Regular Expressions (see separate instructions).
- Where references are signalled in the text by superscript numbers rather than author names, remove the numbers to reduce noise. These can often be removed semi-automatically using Regular Expressions too (see separate instructions).
- Make sure you remove any urls (web addresses), in both the document and the references section. See document on regular expressions for help with identifying and deleting urls.
- If ‘greater than’ (>) and/or ‘less than’ (<) symbols appear in the body of the text (e.g. “Children < 5 years”), these will need to be ‘escaped’. This means replacing < or > with < and > respectively (e.g. Children < 5 years). Similarly, replace ≤ with <= and ≥ with >=
- If the & symbol appears in the text, this will need to be escaped by replacing it with &
Sections
- Each document will have at least one section, consisting in most cases of the main text. (Exception: For journal articles following the IMRAD structure, please see separate instructions below.)
- Each section of the document must have a unique id number in the format s1, s2, s3… sn. The id number is specified as an attribute within the opening section tag, as follows:
<section id="s1" type="text"></section>
- If there is only one section, this will be of the type ‘text’.
- More sections can be added if the document contains an abstract, summary, references or appendices
- If the document contains an abstract (strictly for journal articles) or a summary/executive summary, as in WHO reports (even if it is set within a box or similar), this should be placed in its own section, separate from the main text, as in the following example:
<section id="s1" type="abstract">- Five years into the sustainable development goal(SDG) era, the paradigm shift to integration and prevention needed to achieve health and health-relatedSDGs (HHSDGs) has not meaningfully materialised.- Government leadership and multistakeholder planning are necessary for implementing HHSDGs without marginalising core health issues.</section>
- If the document contains any other frontmatter (e.g. preface(s) or foreword(s)), this should be placed in its own section, separate from the main text. Specify the section type as frontmatter, as in the example below:
<section id="s1" type="frontmatter">…</section>
- If the document contains any backmatter (e.g. postscript(s) or afterword(s)), this should be placed in its own section, separate from the main text. Specify the section type as backmatter, as in the example below:
<section id="s2" type="backmatter">…</section>
- If present, bibliographic references (other than in books) should be placed in a separate section of their own as in the following example:
<section id="s3" type="references">1 United Nations. Sustainable development goals report, 2019. Available: https://unstats.un.org/sdgs/report/2019/The-SustainableDevelopment-Goals-Report-2019.pdf2 GBD 2016 SDG Collaborators. Measuring progress and projecting attainment on the basis of past trends of the health-related sustainable development goals in 188 countries: an analysis from the global burden of disease study 2016. Lancet 2017; 390:1423–59....
</section>
- If present, appendices and annexes should similarly be placed in their own section, keeping the running text as text and capturing the rest (tables, etc.) as visuals. Note that no distinction is made between appendices and annexes, both should be labelled ‘appendix’:
<section id="s3" type="appendix">
- If you add new sections like this, you will also need to add corresponding section tags back into the header file (at the bottom of the file):
<copyright status="copyright_granted"> <holder>Joint United Nations Programme on HIV/AIDS (UNAIDS)</holder> </copyright><section id="s1" type="text"/></section><section id="s2" type="references"/></section><section id="s3" type="appendix"/></section> </document></omcheader>
Note: If the document is a collected volume or report in which different sections are written by different authors, treat it as a single section.
Journal articles following IMRAD structure
- Each section of the document must have a unique id number in the format s1, s2, s3… sn. The id number is specified as an attribute within the opening section tag, as follows:
<section id="s1"></section>
- The first section will contain the abstract (sometimes headed ‘Summary’. Label the section type accordingly (as ‘abstract’ in both cases):
<section id="s1" type="abstract"></section>
- The second section will contain the introduction. Label the section type accordingly:
<section id="s2" type="introduction"></section>
- The third section will contain the methods section. Label the section type accordingly:
<section id="s3" type="methods"></section>
- The fourth section will contain the results. Label the section type accordingly:
<section id="s4" type="results"></section>
- The fifth section will contain the discussion. Label the section type accordingly:
<section id="s5" type="discussion"></section>
- As above, when you add new sections like this, you will also need to add corresponding section tags back into the header file (at the bottom of the file):
<copyright status="copyright_granted"> <holder></holder> </copyright><section id="s1" type="abstract"/></section><section id="s2" type="introduction"></section><section id="s3" type="methods"></section><section id="s4" type="results"></section><section id="s5" type="discussion"></section> </document></omcheader>
Optional tags
- <title>…</title> The title (including subtitle) of any document will already have been recorded in the header file, which means if it doesn’t appear in the text file the document will still validate. The title is therefore optional in this sense. Nevertheless, you should include the title/subtitle in the text file and place it within the above tags in order to make it available for analysis as part of the document.
- <keywords>….</keywords> Keywords, when present, go between <keywords> tags, separately from abstracts.
- <textbox> … </textbox> Any blocks of text that interrupt the main text (such as ‘panels’ in the Lancet/UNAIDS commission on AIDS) should be moved to the end of the section in which they are found and placed within these tags.
Visuals
- In the same folder on your machine’s hard drive, save (as a .png file) a copy of each of the visuals (photos, tables and graphs) used in the document (either by copying and pasting it, or using a screenshot tool). Give each figure a unique and consistent filename e.g. omc000001-figure-1.png, omc000001-figure-2.png, omc000001-figure-3.png… There is no need to distinguish in the filename between tables and other types of visuals: all can be labelled as figures.
- IMPORTANT: Do not include logos such as those of the UN, WHO, etc.
- Use Desnoyer’s (2011) taxonomy to categorise these graphics. For example, the following figure would be coded as below:
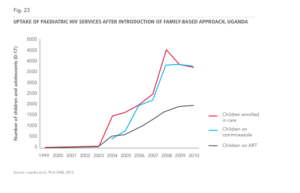
<visual><image uri="oomc000001-figure-23.png" caption="Fig. 23 UPTAKE OF PAEDIATRIC HIV SERVICES AFTER INTRODUCTION OF FAMILY-BASED APPROACH, UGANDA" description="Line graph/><class><analogram><curvigram><curvigramfamily axis="cartesian" line="curved"></curvigramfamily> </curvigram></analogram></class></visual>
The following table would be coded as follows:
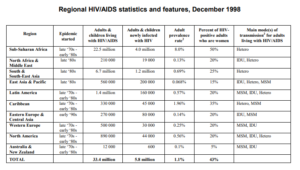
<visual><image uri="omc000002-table-2.png" caption="Regional HIV/AIDS statistics and features, December 1998" description="table"/><class><typogram><cellulogram><cellulogramfamily><format type="quadrangular"></format> </cellulogramfamily> </cellulogram></typogram></class></visual>
Abbreviations and glossaries
Save abbreviation lists and glossaries (see examples below) as visuals. In the above taxonomy, these should be classed as cellulograms, similarly to tables.
Lists of abbreviations and glossaries should be included within the frontmatter section (<section id="s1" type="frontmatter">).

Help with categorizing images:
A cheatsheet with many more examples of how to categorize different kinds of visual can be found by following this link: https://luzs.gitlab.io/oslomedicalcorpus/DesnoyersTaxonomyHTML/Taxonomy.htm. Additional information is also available via a designated Teams channel.
Visuals with continuous text:
In a limited number of cases, visuals may contain extended stretches of continuous text (see example below). If the continuous text in such visuals is convertible into text format (e.g. via OCR or pdftotext), it should be retained as text and captured as visual (scriptogram).

Captions, Descriptions and Placement of Visuals
Where a visual is accompanied by a caption, the caption must be included as an attribute of the visual. If there is no caption you should add a description of what is shown in the visual, also as an attribute of the visual.
The description tag is optional. Remove it from the file if the visual is already accompanied by a caption, in case you don’t need to give extra information.
Important: Visuals and their accompanying captions/descriptions should be placed at the beginning of the nearest sentence they appear near to if their placement in the original document interrupts the main text.
Copyright for Visuals
Where separate copyright information is available for visuals (e.g. credits or copyright ownership), this should be recorded at the end of the header file only, as in the following example:
<?xml version=”1.0″ encoding=”UTF-8″ standalone=”no”?>
<!DOCTYPE omcheader SYSTEM “omcheader.dtd”>
<omcheader>
<document filename=”omc000015″ publication_date=”2017″ capture_date=”2021″ format=”manual”>
<title>Communicating risk in public health emergencies. A WHO guideline for emergency risk communication (ERC) policy and practice</title>
<author>
<firstname></firstname>
<lastname>WHO</lastname>
</author>
<organisation name=”WHO”/>
<copyright status=”creative_commons”>
<holder>WHO</holder>
</copyright>
<comments>CC BY-NC-SA 3.0 IGO</comments>
<visual_copyright>
Photo credits: WHO/D. Spitz, WHO/A. Bhatiasevi, WHO/E. Soteras Jalil,
WHO/C. Black, WHO/G.Moreira, WHO/A. Esiebo, WHO/W. Romeril,
WHO/H. Ruiz, WHO/V. Houssiere, WHO/I. Vrabie, WHO/U. Zhao, WHO/AMRO, WHO/N. Alexander.
</visual_copyright>
….
</section>
</document>
</omcheader>
Validation
As with the header file, the last step of this process is to check that your file validates against the OMCTEXT.DTD. Follow the validation instructions for header files above.
Final Check
At the end of this process, you should have saved on your hard drive and ready for processing:
- An xml file (labelled e.g. omc000001.xml) containing the main body of the text and validated against the OMCTEXT.DTD
- A header file (labelled e.g. omc000001.hed) containing metadata about the text, validated against the OMCHEADER.DTD
- Saved copies of all of the visuals contained within the text, each with a unique and consistent filename (e.g. omc000001-figure1.png) which corresponds to its URI (Uniform Resource Identifier) at the corresponding position in the XML file.